DRAM에 대해 설명해보세요.
DRAM은 트랜지스터(Transistor) 하나(1T)와 캐패시터 Capacitor 하나(1C)로 구성된다. 이는 하나의 트랜지스터만으로 비트 요소를 구축하는 것이 불가능하기 때문이다. 대신 DRAM의 메모리 셀은 MOS 트랜지스터를 통해 접근하는 작은 캐패시터에 정보를 저장하도록 구성되어 있다.
DRAM 한 비트에 대한 기억 셀을 보면, 워드 선택선에 HIGH 전압을 인가하면 접근할 수 있다. 1을 저장하려면 비트에 접근하고 비트선에 HIGH 전압을 인가하여 ‘on’ 트랜지스터를 통해 캐패시터를 충전한다. 0을 저장하려면 비트선에 LOW 전압을 인가하여 캐패시터를 방전시킨다. 반대로 상태값을 읽기 위해서는 AL에 전류를 넣어준다. 캐패시터에 전하가 저장되어 있을 경우(1인 경우) 전하가 DL로 빠져나올 것이고, 전하가 없는 경우(0인 경우)는 DL로 빠져나오는 값이 없을 것이다.
이 방법의 장점은 플립플롭을 사용하는 SRAM보다 IC칩에서 더 적은 공간을 차지한다는 점이다. 메모리는 상대적인 물리적인 크기의 SRAM의 용량보다 약 4배가 된다.
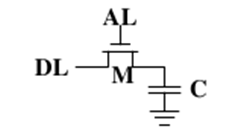
DRAM 셀을 읽는 과정을 보다 자세히 살펴보면, 비트선은 먼저 HIGH와 LOW 사이의 중간 전압으로 예비 충전되고, 워드 선택선이 HIGH로 된다. 축전기 전압이 HIGH이냐 LOW이냐에 따라, 예비 충전된 비트선은 약간 높아지거나 낮아진다. 감지 증폭기가 이 작은 변화를 검출하고, 그에 따라 1이나 0으로 복구한다. 셀을 읽으면 축전기에 저장된 원래 전압이 파괴되므로 읽은 다음 복구된 데이터를 셀에 다시 써야 한다. DRAM 셀 내의 축전기는 캐패시턴스가 매우 작지만, 이에 접근하는 MOS 트랜지스터의 임피던스가 매우 크다. 따라서 HIGH 전압이 LOW로 보이는 점까지 방전하는 시간은 상대적으로 매우 길다. 이러한 방법으로, 캐패시터는 비트의 정보를 저장할 수 있다.
메모리가 내용이 없어져서 100ms 마다 다시 부팅해야 한다면 컴퓨터를 사용할 수 없을 것이다. 따라서 DRAM 기반 메모리 시스템은 모든 메모리 셀을 주기적으로 갱신하기 위하여 리프레시 사이클(Refresh Cycle)을 사용한다. 이는 차례대로 각 셀의 어느 정도 저하된 내용을 D래치로 읽어 들이고 확실한 LOW나 HIGH 값을 다시 기록하는 동작이 지속적으로 일어남을 뜻한다.
여기서 DRAM은 플립플롭을 사용하는 SRAM에 비해 큰 불편이 있다. 한 비트는 메모리 칩에 지속적으로 전력을 공급하는 동안 플립플롭에 영원히 저장된 채 남아있을 것이다. 그러나 충전된 축전기는 반드시 그것의 전하를 잃고 고립된 채로 남아 있는다. (복잡한 IC에서 초기에 충전되지 않는 축전기에 어떤 충전을 인가할 때 누전 메커니즘이 존재하는 것이 가능하다. ) 그러므로 축전기-저장 메모리에 저장 장소를 보존시키기 위해 저장된 비트가 명백하게 인식되는 동안에 각 축전기에 저장을 요하는 비트에 대응하는 완전 충전 값으로 복귀되어야 한다. 이와 같은 초기 충전으로의 복귀는 각 축전기의 2ms를 초과하지 않는 범위에서 보충되어야 한다.
이와 같이 일정한 보충 활동이 필요하기 때문에 축전기-저장 메모리는 정적 메모리로 불리는 SRAM에 비하여 동적 메모리(Dynamic RAM; DRAM)라고 불린다. 이러한 보충 활동 중에는 상태값에 접근할 수 없기 때문에, DRAM의 성능은 제한될 수 있다. 하지만 적은 메모리 용량에서와는 달리 대규모 메모리 용량이 필요할 때 DRAM를 사용하는 것은 이점이 크다. DRAM셀의 크기는 SRAM에 비해 훨씬 더 작으며, 안에 들어가는 소자의 구성도 상대적으로 단순하기 때문에 효율적인 구성이 가능하기 때문이다.

[DRAM 세대별 최신 현황]
현재 DRAM 시장은 DDR5, LPDDR5X, HBM3E의 세 축을 중심으로 급격히 재편되고 있다. DDR5(JEDEC JESD79-5, 2020년 표준 확정)는 DDR4 대비 2배 이상의 대역폭을 제공하며 인텔 12세대 플랫폼(Alder Lake, 2021년) 이후 서버·PC 시장에서 빠르게 확산되고 있다. LPDDR5X는 최대 8533Mbps의 속도로 스마트폰·엣지 AI 기기에 탑재되고 있으며, HBM3E(High Bandwidth Memory 3E)는 AI GPU 연산용으로 TSV 기술을 통해 DRAM 다이를 수직 적층하여 초당 1.2TB 이상의 대역폭을 실현한다. SK하이닉스는 2024년부터 NVIDIA H200 GPU 전용 HBM3E를 공급하며 AI 메모리 시장을 주도하고 있다.
커뮤니티 Q&A
위 이론과 관련된 게시글이에요.
이해가 안 되거나 궁금한 점이 있다면 커뮤니티에 질문해 보세요!
게시글 작성하기